AWS Serveles criando Funcoes Lambdas com Nodejs
20 de maio de 2019 • ☕️ 3 min read
Translated into: Português do Brasil
Read the original • • View all translated posts
Recentemente, recebi um badge da AWS Serverless Foundation aqui na Ao.com no Reino Unido e achei que seria a oportunidade perfeita para começar meu blog.
Há muito tempo venho pensando em escrever um blog e tentar compartilhar mais sobre o que estou aprendendo.
O objetivo principal é estar compartilhando com a comunidade um pouco da minha experiencia.
E a internet é um lugar fantástico para essa missão específica, então vamos compartilhar mais!
A AWS Serverless Foundation foi uma série de sessões dadas pela nossa equipe de DevOps aqui na Ao.com.
Para ser certificado no final deste processo, você devera ser capaz de criar e implantar uma aplicacao completo usando a estrutura “Serverless”.
Eu estava construindo este blog na época (vou criar um post sobre isso em breve) e estava pensando em criar um componente em React que exibisse o número total de seguidores que eu tenho no Twitter e no Instagram.
Com isso em mente, achei que seria o candidato perfeito para uma abordagem “Serverless”, usando as funções Lambdas para buscar e copiar os dados e servi-los como uma API endpoint para que meu blog pudesse consumi-los.
Comecei a pensar em como seria o meu projeto, e o diagrama a seguir ajudara a representá-lo melhor:
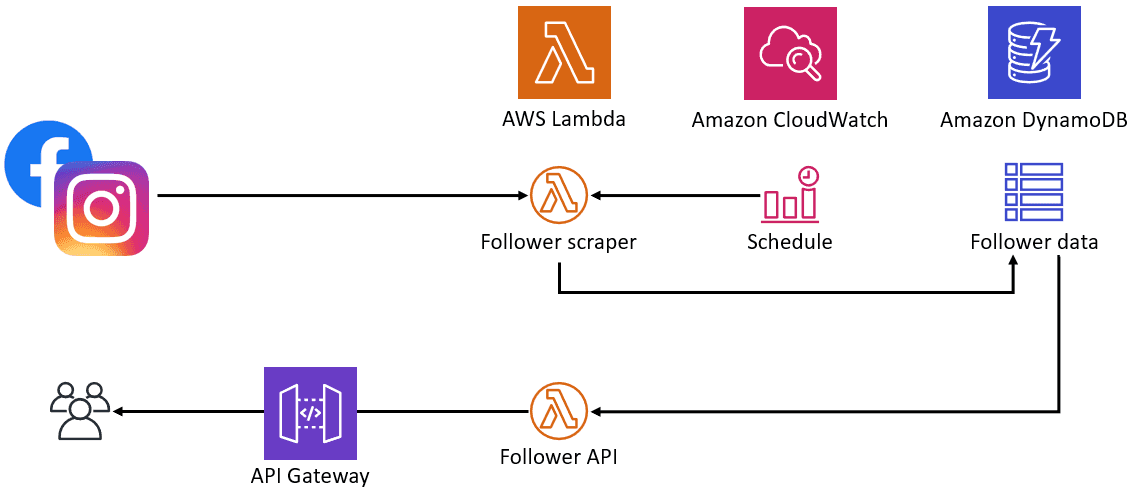
As funcoes Lambda são famosas por serem de “baixo custo”, e você paga exclusivamente pelo que utiliza, sem a necessidade de se preocupar com toda uma infra-estrutura online 24 por 7 (Pagando pelo uptime).
E a melhor parte é que você pode executar até 1MI de vezes sem pagar um centavo, o que faz desse projeto perfeito para fins de aprendizagem.
Você pode encontrar mais informações sobre o assunto no seguinte link
Você podera encontrar mais informações sobre meu projeto no meu GitHub clicando aqui: Github
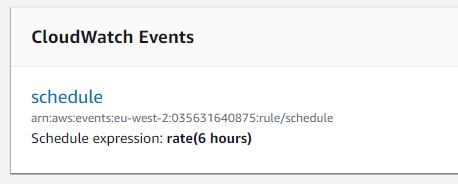
O projeto consiste em duas Lambdas diferentes, o primeiro responsável por puxar os feeds do Facebook e do Instagram periodicamente para obter o número total de “likes”. Ela usa o Amazon CloudWatch para fazer com que isso aconteça sem problemas como cron job a cada 6 horas.
Depois desse ponto, as funções do Lambda salvam os dados no DynamoDB. A melhor parte disso é que usar o Node.JS torna o processo ainda mais confortável porque converte o objeto em um armazenamento de documentos que ficaria assim.
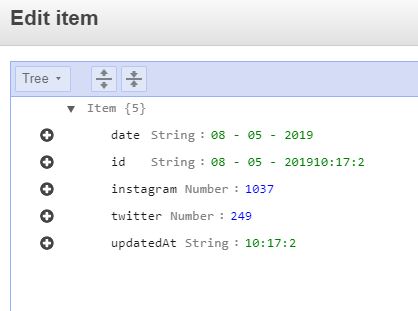
Você teria uma chave primária para identificar seu objeto, e você poderia ter quantos atributos você gostaria, no meu exemplo, eu criei um para armazenar a data e isso me ajuda a classificar por data (SortBy), eu tenho o Instagram e Twitter para armazenar os números de seguidores e o horário atualizado para salvar a hora em que foram extraidos.
A primeira Lambda é disparado a cada seis horas, para capturar novos dados do meu Instagram e Twitter, e o trabalho pode ser feito usando um evento do CloudWatch usando expressões cron.
O último trabalho é feito pelo segundo Lambda, que é responsável por consultar os dados e converter-los para JSON.
O arquivo de configuração ficaria assim:
serverless.yml
service: robotscraper
provider:
name: aws
runtime: nodejs8.10
region: eu-west-2
iamRoleStatements: # permissions for all of your functions can be set here
- Effect: Allow
Action: # Gives permission to DynamoDB tables in a specific region
- dynamodb:DescribeTable
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: 'arn:aws:dynamodb:eu-west-2:*:*'
functions:
getLikes:
handler: src/index.getLikes
events:
- http:
path: api/likes
method: get
cors: true
taskRunner:
handler: src/lib/scraper.taskRunner
events:
- http:
path: api/likes/update
method: get
cors: true
plugins:
- serverless-webpack
- axios
- cheerio
- serverless-offline
package:
individually: true
custom:
webpack:
webpackConfig: ./webpack.config.js
includeModules: true
resources: # CloudFormation template syntax
Resources:
likesapi:
Type: 'AWS::DynamoDB::Table'
DeletionPolicy: Retain
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
- AttributeName: date
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
- AttributeName: date
KeyType: RANGE
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: 'likesapi'
Como você pode notar na configuração acima, criamos um endpoint da API e o evento acontece quando você atinge o endpoint “/API/links” com uma solicitação GET.
{
"data": [
{
"twitter": 250,
"date": "12 - 05 - 2019",
"instagram": 1036,
"id": "12 - 05 - 20196:55:12",
"updatedAt": "6:55:12"
}
]
}
Isso é muito útil para o meu caso, que consiste em consumir esses dados do meu blog.
E o trabalho está finalizado!
Parece mais complicado do que é, e esse é o lado positivo da estrutura sem servidor, ele ajuda você a configurar rapidamente tudo isso e manter seu foco no que gostamos, no código.
Você também pode instalar o pacote Serverless-Offline e executar e testar seu ambiente Lambdas em modo “Dev”, o que torna nossa vida ainda mais confortável.
Eu aprendi muito depois dessa experiência e pude ver os benefícios de ter um aplicativo “Serverless”.
Ele nos traz muitos muitos benefícios, no meu blog em que o hospedei na Amazon S3, como um site estático gerado usando o Gatsby faz todo o sentido estar usando o as funcoes Lambdas.
Espero que você tenha gostado deste post e me avise se tiver algum comentário.
Att
Jean Rauwers