AWS Serverless with Node and Lmbdas functions
May 20, 2019 • ☕️ 3 min read
Translated into: Português do Brasil
I was recently awarded an AWS Serverless Foundation Badge at Ao.com, and I thought it would be the perfect opportunity for me to start my blog.
For a long time, I have been thinking about to write a blog and try to share more about what I’m learning. The primary goal is to be giving back to the community.
And the internet is a fantastic place for this specific mission, so let’s share more!
The AWS Serverless Foundation was a series of sessions given by our DevOps team at ao.com.
To be awarded in the final of this process, you should be able to build and deploy a complete application using the Serverless framework.
I was building this blog by the time ( Will create a blog post about it soon ) and was thinking about to create a React component that would display the total number of followers I have on Twitter and Instagram.
With that in mind, I thought it would be the perfect candidate for a serverless approach using Lambdas functions to fetch and scrape the data and serve it as an API endpoint so that my blog could consume it.
I started thinking about how my project would look like, and the following diagram can help me to represent it better:
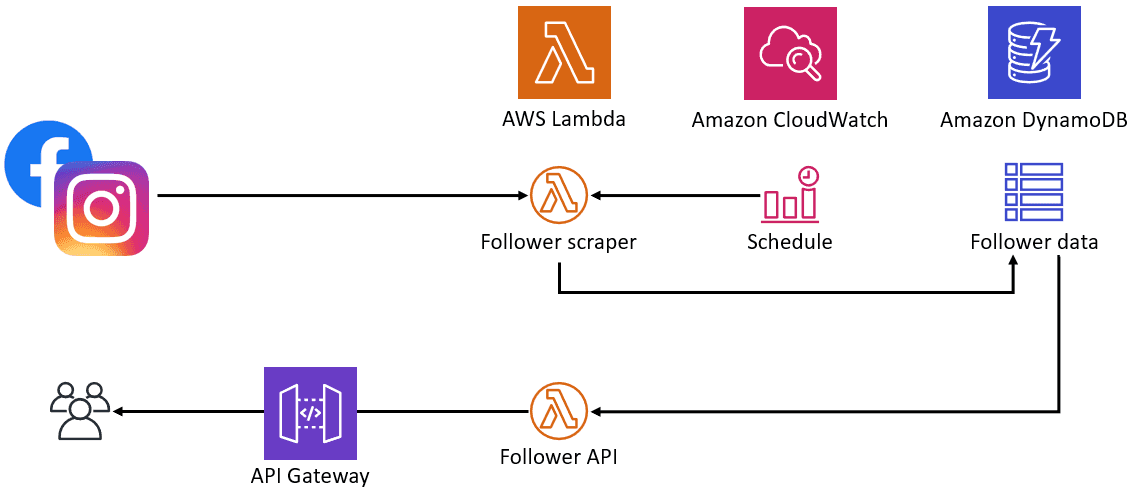
The Lambda is famous for being “low cost”, and you pay exclusively for the usage, without the need to be worried about an entire infra-structure online 24 by 7 (Paying for uptime).
And the best part is that you can run up to 1MI of times without a pay a penny, it is perfect for learning purposes such mine.
You can find more about the topic on the following link
You can find more about my project on my GitHub clicking here: my github
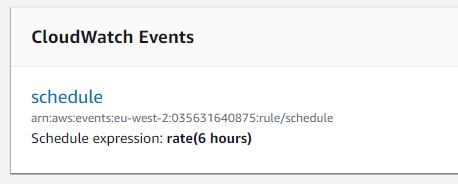
The project consists of two different Lambdas, the first one responsible for pulling the Facebook & Instagram feeds periodically to scrape the total number of likes, it’s using the Amazon CloudWatch to make it happen smoothly every 6 hours.
After this point, the Lambda functions save the data to the DynamoDB. The better part of it is that using Node.JS makes the process even more comfortable because it converts the object into a document store that would look like that.
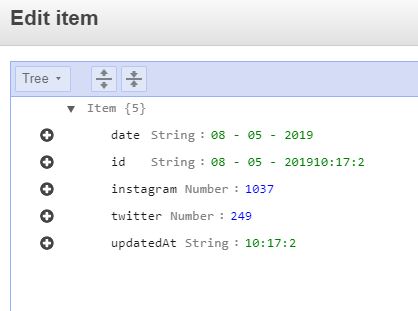
You would have a Primary Key to identify your object, and you can have as many attributes as you would like, on my example, I created one to store the date and it does help me to sort by date, I have the Instagram and Twitter to store the follower numbers and the updated time to save what time it was created.
The first Lambda is fired every six hours, to scrape new data from my Instagram and Twitter, and the job can be done using a CloudWatch event using cron expressions.
The last job is done by the second Lambda, which is responsible for query the data and parses it to JSON.
The config file would look like this:
serverless.yml
service: robotscraper
provider:
name: aws
runtime: nodejs8.10
region: eu-west-2
iamRoleStatements: # permissions for all of your functions can be set here
- Effect: Allow
Action: # Gives permission to DynamoDB tables in a specific region
- dynamodb:DescribeTable
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: 'arn:aws:dynamodb:eu-west-2:*:*'
functions:
getLikes:
handler: src/index.getLikes
events:
- http:
path: api/likes
method: get
cors: true
taskRunner:
handler: src/lib/scraper.taskRunner
events:
- http:
path: api/likes/update
method: get
cors: true
plugins:
- serverless-webpack
- axios
- cheerio
- serverless-offline
package:
individually: true
custom:
webpack:
webpackConfig: ./webpack.config.js
includeModules: true
resources: # CloudFormation template syntax
Resources:
likesapi:
Type: 'AWS::DynamoDB::Table'
DeletionPolicy: Retain
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
- AttributeName: date
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
- AttributeName: date
KeyType: RANGE
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: 'likesapi'
As you can notice on the above config we have created an API endpoint and the event happens when you hit the “/API/links” endpoint with a get request.
{
"data": [
{
"twitter": 250,
"date": "12 - 05 - 2019",
"instagram": 1036,
"id": "12 - 05 - 20196:55:12",
"updatedAt": "6:55:12"
}
]
}
This is very helpful for my use case, which consists of fetching this data from my blog app.
And the job is done!
It seems more complicated than is, and that is the bright side of the serverless framework, it helps you to quickly set up all this stuff and keep your focus on the code.
You can also install the Serverless-Offline package and run and test your Lambdas in Dev environment, which makes our life even more comfortable.
I have learned lots after this experience, and I could see the benefits of having a serverless application.
It has lots of benefits for the right use case, on my blog where I have it hosted on S3 bucket as static website generated using Gatsby it makes perfect sense to be using AWS Lambdas as I am using serverless technology.
I hope you have enjoyed this post and please let me know if you have any feedback.
Regards,
Jean Rauwers